Migrating to Veda 2.0
Caution
Familiarity with the model database and Veda_FE/BE are necessary to migrate efficiently. I request users to not delegate this task to new members of the team.
This is an incomplete list of things to keep in mind, or do, when migrating VEDA_FE models to Veda2.0
Before you start
- First time you import a new model folder, you may need resolve three types of issues that were working OK with old veda:
- Multiple Veda tables in the same Excel range
Need to insert empty rows/cols around tables
- Duplicate column names
FI_T is the only table that supports duplicate column names like Veda_FE used to: the rightmost non-empty value over the duplicate columns in each row will survive. Other tags will report duplicate column headers that will need to be resolved by the user.
- Veda2 needs scenario names to be unique across file types
In case there is a ScenDem_BASE file in the SuppXLS\Demands folder then rename it to something like ScenDem_BASE_dem because BASE is reserved for the base-year templates + BY_Trans.
Veda_SnT to Excel migration.xlsm, which is in the new Veda folder, can be used to migrate sets and table definitions from a VEDA_SnT.MDB file.
Things that are different
- Interpolation settings table in SysSettings needs to be converted to a MIG table.
Need to use an INS table for specifying values for year=0 when there is no seed value.
- VEDA_FE used to allow defining interpolation options in SysSettings also with TFM_INS tables, which could be used for generating IE options irrespective of existing declarations in Base/SubRES/other scenario files. This is no longer possible in VEDA2. Any redefinition (via any tag in SysSettings) of interpolation options defined in Base/SubRES is ignored in Veda2.0.
The thinking is that SysSettings is meant for defining “default” interpolation options.
Any other scenario file can be used to “update” interpolation options that are defined in Base/SubRES, but interpolation options defined and redefined in multiple files could create confusion.
Text values (like for PRC_TSL) will need a new tag - TFM_INS-txt.
UC sets declaration, like “~UC_Sets: R_E: AllRegions”, is required for Veda2.0 to process UC tables. AllRegions was assumed by default in Veda_FE if this declaration was missing.
Veda2.0 prohibits new investment in processes with existing stock (via NCAP_BND(0,UP)=2), but this is not done for processes on which any NCAP_BND is specified. Users can control this using an INS table with attrib_cond = RESID (or PASTI).
- Not supported:
comm1/comm2 in matrix form trade links declarations
- Trade parameter declarations in matrix form (~TRADE_Param)
There will be a utility to migrate trade links and parameters to alternate formats
- Sets-<Model name>.xls with sets declarations expected in model root folder, if user-defined sets are used in any TFM table.
There is a utility (Veda_SnT to Excel migration.xlsm) to export your current sets from a Veda_SnT.MDB file, if you don’t already have them in Excel. This utility also exports VBE views.
Column “other_indexes” to be renamed to UC_N in any INS/DINS tables used to declare UC names.
Ignore characters are not supported in unsupported columns. Exceptions: Unit, End-Use, TechDesc,..
IRE_FLOSUM: bug fix. other_indexes should hold commodity2
- Sheet names in SubRES files had to start with sector names. This restriction has been removed
techs might appear in new regions unless controlled via AVA.
- “Deact~UC_T” was actually not respected earlier, but now it will be.
The previous version searched for <tag>, and the new one looks for <tag>*
Blank cells in header rows used to mark the end of tables. Now each table will be read as per the “current region” of the table tag.
- Column position of FI_T/UC_T tags are not important anymore. Further, it had to be - all index columns followed by value columns - in VEDA_FE, but they can be arranged freely now.
extra columns would appear from tables where FI_T/UC_T tags were misplaced
- No QC of process/commodity/UC names. <list of characters> used to be replaced with “_”.
Now the DD files are always written with <’> around each element and all names are retained as in their original form.
- The default year has been changed from the first milestone year to the start year. For example, if first period was 2008-2012, the default year would be 2010 in the previous version and 2008 in Veda2.0.
There is a new tag ~defaultyear: <year> to have direct control on this value. It defaults to start year.
Table ~ImpSettings in SysSettings is no longer read. Dummy variables control is available under Tools – user options.
Veda2.0 does not provide any default costs for dummy imports. Very high default costs for dummy imports often created numerical issues for solvers. Users should use appropriate costs for IMP*Z processes in SysSettings or some other scenario file.
- Veda2.0 doesn’t refresh files while reading them
- Veda2.0 opens files as Excel objects to search for tags and to establish the range to be read for each tag, and closes them without saving. Then they are read as XML via Exceldatareader in a second pass. Multiple files are processed in parallel for searching as well as reading. This approach has resulted in a major performance improvement and it is far more robust.
Files are still refreshed and saved in cases where Veda writes to them – any scenario or trans file with FILL tables and parametric scenarios.
Old Veda makes temp copies of files before reading them, so they are refreshed if the calculation mode is set to automatic. Each file is read in via an Excel object, which makes Excel practically unusable during the entire Sync process.
- ~RFInput and ~SFInput were used to write GAMS code in RUN and scenario files, respectively. These tags are not supported anymore. Instead, there are RFCmd* and SFCmd* attributes (See Information - TIMES Attributes) for this purpose. Use Other_indexes col to write the commands, which will be sorted by the values assigned to these attributes.
If you have commas or single quotes in the commands, then use a DINS-AT table, with a dummy PSET_PN col.
FILL/FILL-R tables: If qualifying values exist in multiple scenarios, only ones from the “last scenario”, like seed values for UPD/MIG tables, will be returned. VEDA_FE would return values from all scenarios. If multiple scenarios are needed for some reason, then they can be declared (comma-separated) in “SourceScen” col.
~TFM* tags are expected to be on the top left of tables, but VEDA_FE used to read all columns in the range of tags, even if they were to the left of the tag itself. Veda2 ignores cols to the left to avoid the duplicate columns issue.
Update and Migrate tables will not see seed values from the scenario that they are specified in.
Negative (exclude) filters were combined with AND by default in VEDA_FE, but they are combined with OR in Veda2.0.
COST was not shown an alias of ACT_COST in the Attribute Master, but it worked like one for non-IRE processes in VEDA_FE. Veda2.0 does not make this exception.
In parametric scenario files, Veda_FE interpreted a single number in the ~InputCell field as a range from 1 to that number. For example, specifying ~InputCell: 5 would generate scenarios 1 through 5. To create only scenario #5, you had to explicitly write 5-5. In Veda2, this behavior has changed. A single number in ~InputCell is now interpreted as it is, meaning 5 will generate only scenario #5, not a range.
Migration steps
- Download Veda
Get the latest TIMES code from this link.
Make a copy of the model and activate in current Veda
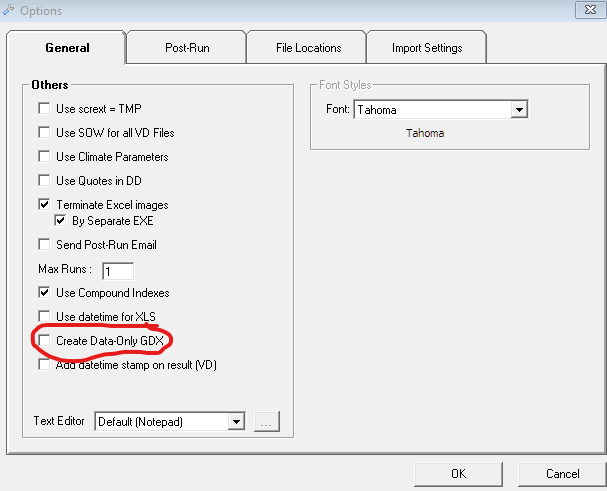
Check option “Create data-only GDX” under Tools-user options
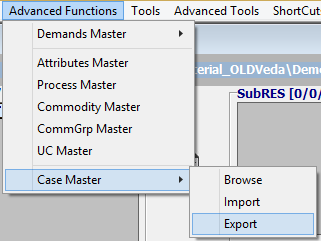
- To export current case definitions
- Go to Advanced Functions – Case Master – Export
- Run a Ref case from current Veda
Edit the templates for points in Things that are different.
Install and launch Veda2.0 and point it to the model
Convert XLS to XLSX/M from Tools menu
Migrate set and table definitions using Veda_SnT to Excel migration.xlsm
- Synchronize
You may have to edit templates for conflicting ranges and duplicate col names in tables
Will need to synchronize from scratch in this case
Open the Run Manager and set GAMS root path
- Click Restore cases under Settings
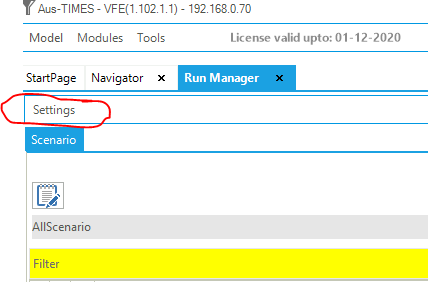
This will import cases as scenario groups
File must be named <modelname>_exportedCases.csv
Create a Ref case and Solve
Compare input data (GDXDiff) and results.